This article was originally featured on Known magazine.
Every human being starts out as just one fertilized egg. In adulthood, that single cell has turned into about 37 trillion cells, many of which continue to divide to create the same amount of fresh human cells every few months.
But those cells face a formidable challenge. The average division cell should copy – perfectly – 3.2 billion base pairs of DNA, about once every 24 hours. The cell’s replication machinery does this wonderfully, copying genetic material at a hurried rate of about 50 base pairs per second.
Still, that’s far too slow to duplicate the whole thing human genome. If the cell’s copying machines started at the end of each of its 46 chromosomes at the same time, it would complete the longest chromosome — number 1, with 249 million base pairs — in about two months.
“The way cells naturally get around this is they start replicating in multiple places,” said James Berger, a structural biologist at Johns Hopkins University School of Medicine in Baltimore, who co-authored an article on DNA replication in eukaryotes in the 2021 Annual Review of Biochemistry. Yeast cells have hundreds of possible sources of replication, as they are called, and animals such as mice and humans have tens of thousands of them scattered throughout their genomes.
“But that poses its own challenge,” says Berger, “which is, how do you know where to start and how do you time everything?” Without precision control, some DNA can be copied twice, causing cellular pandemonium.
It’s especially important to keep the DNA replication kickoff tight to avoid that pandemonium. Today, researchers are moving toward a full understanding of the molecular checks and balances that have evolved to ensure that each origin initiates DNA copying once, to produce exactly one completely new genome.
Do it right, do it fast
Bad things can happen if replication doesn’t start correctly. To copy DNA, the DNA double helix must open, and the resulting single strands — each of which serves as a template for building a new, second strand — are vulnerable to breakage. Or the process hangs. “You really want to solve replication quickly,” said John Diffley, a biochemist at the Francis Crick Institute in London. Problems during DNA replication can cause the genome to become disorganized, which is often a major step on the road to cancer.
Some genetic diseases also result from problems with DNA replication. For example, Meier-Gorlin syndrome, which involves short stature, small ears, and small or no kneecaps, is caused by mutations in several genes that help trigger the DNA replication process.
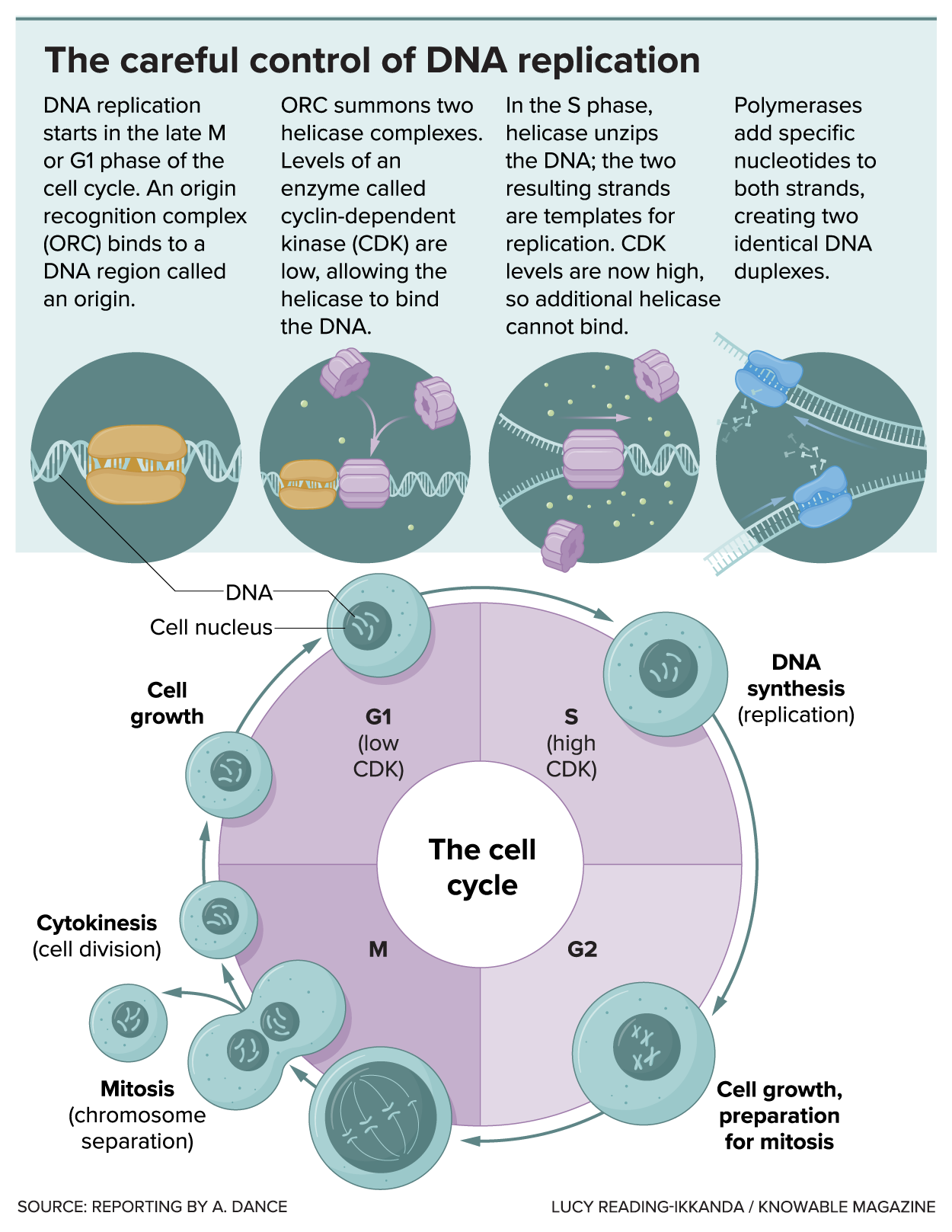
It takes a tightly coordinated dance involving dozens of proteins before the DNA copying machine starts replicating at the right point in the cell’s life cycle. Researchers have a pretty good idea of which proteins do what because they’ve managed to get DNA replication to take place in cell-free biological mixtures in the lab. They recreated the first critical steps in starting replication using yeast proteins– the same kind used to make bread and beer – and they mimicked much of the whole replication process using human versions of replication proteinsat.
The cell controls the start of DNA replication in a two-step process. The whole purpose of the process is to control the actions of a crucial enzyme – called a helicase – that unwinds the DNA double helix in preparation for copying it. In the first step, inactive helicases are loaded onto the DNA at the origin, where replication begins. During the second step, the helicases are activated to unwind the DNA.
Done (load the helicase)…
The process begins with a cluster of six proteins at the origin. This cluster is called ORC formed as a double-layered ring with a nifty notch that allows it to slide onto DNA strands, Berger’s team has found.
In baker’s yeast, a favorite for scientists studying DNA replication, these starting sites are easy to recognize: they have a specific DNA core sequence of 11 to 17 letters, rich in chemical bases of adenine and thymine. Scientists have watched ORC grab hold of the DNA and then slide on, scan for the origin string until he finds the right place.
But in humans and other complex life forms, the starting sites aren’t so clearly delineated, and it’s not entirely clear what causes the ORC to settle down and take hold, says Alessandro Costa, a structural biologist at the Crick Institute who, with Diffley, wrote on the initiation of DNA replication in the 2022 Annual Review of Biochemistry. Replication seems more likely to start where the genome—normally tightly coiled around proteins called histones—has come loose.
Once ORC has settled onto the DNA, it attracts a second protein complex: one that includes the helicase that will eventually unwind the DNA. Costa and colleagues used electron microscopy to find out how ORC lures in first a helicase, then another. The helicases are also ring-shaped and each opens to wrap around the double-stranded DNA. Then the two helicases close again, facing each other on the DNA strands, like two beads on a string.
At first they just sit there, like cars with no gas in the tank. They have not yet been activated and for the time being the cell will continue as normal.
Get ready (activate the helicase)…
Things kick into high gear when a crucial molecule called CDK waves the green flag, kick-starting chemical steps that lure in even more proteins. One is DNA polymerase – what Costa calls the “typewriter” that will build new strands of DNA – which attaches to each helicase. Others activate the helicases, which can now burn energy to haul the DNA along.
As this happens, the helicases change shape, pushing on one strand of DNA and pulling on the other. This puts pressure on the weak hydrogen bonds that normally hold the two strands together through the bases – the As, Cs, Ts and Gs that make up the rungs of the DNA ladder. The two strands are torn apart. Costa and colleagues observed how the two helicases unscrew the DNA between themand they’ve seen how the helicases keep the unbound bases stable and out of the way.
To go!
At first, both helicases are wrapped around both strands of DNA and can’t get very far this way because they’re facing each other and just run into each other. But then they each undergo a position change, with one or the other DNA strand being spewed out of the ring. Now that they are separate, they can crowd past each other and replication is fast.
Each helicase motor along its single strand, in the opposite direction from the other. They leave behind the origin and tear apart those hydrogen-bonded base pairs as they travel. The DNA polymerase is right behind it and copies the DNA letters as they are freed from their partners.
CDK’s second job is to prevent any more helicases from jumping onto the origin. Thus, there is one start of replication per origin, ensuring correct copying of the genome, although copying does not start at the same time in every place. The entire process of DNA replication, in human cells, takes about eight hours.
There is still plenty to work out. For starters, the DNA being copied is not a naked double helix. It is wrapped around histones and attached to numerous other proteins that are in the process of turning genes on or off making RNA copies of the genes. How do these displacing proteins influence each other and prevent them from getting in each other’s way?
In addition to this fascinating, fundamental biology – a remarkable process essential to all life on Earth – there are implications for diseases such as cancer. Scientists already know that misreplication can destabilize DNA, and an unstable genome prone to mutation may be an early hallmark of cancer development. And they are further investigate links between replication proteins and cancer.
“I think there are opportunities for therapeutic interventions for these systems,” says Berger, “once we have a good understanding of how they work and what they look like.”
This article originally appeared in Known magazine, an independent journalism initiative of Annual Reviews. Sign up for the newsletter.




